
Word2Vec 参数影响实验报告
实验环境
- 数据集:text8 语料库(约 17M 词)
- 评估数据集:WordSim353(词对相似度人工标注数据)
- 评估指标:斯皮尔曼等级相关系数(Spearman's Rank Correlation)
- 工具库:Gensim 4.x
- 基准配置:vector_size=200, window=10, min_count=10, sg=0 (CBOW)
实验目标
探究 Word2Vec 模型中不同参数对词向量质量的影响,使用 text8 数据集训练, 在 WordSim353 数据集上评估。
实验设计
实验方案
采用控制变量法,每次只改变一个参数,观察其对模型性能的影响:
| 实验编号 | 变量参数 | 测试值 | 固定参数 |
|---|---|---|---|
| 实验1 | vector_size(词向量维度) | 50, 100, 150, 200, 300 | window=10, min_count=10 |
| 实验2 | window(窗口大小) | 3, 5, 8, 10, 15 | vector_size=200, min_count=10 |
| 实验3 | min_count(最小词频) | 5, 10, 20, 50 | vector_size=200, window=10 |
评估方法
使用 WordSim353 数据集评估词向量质量:
- 对数据集中的词对计算余弦相似度
- 将模型预测相似度与人工标注相似度进行比较
- 计算斯皮尔曼等级相关系数(值越接近1表示模型越好)
实验结果
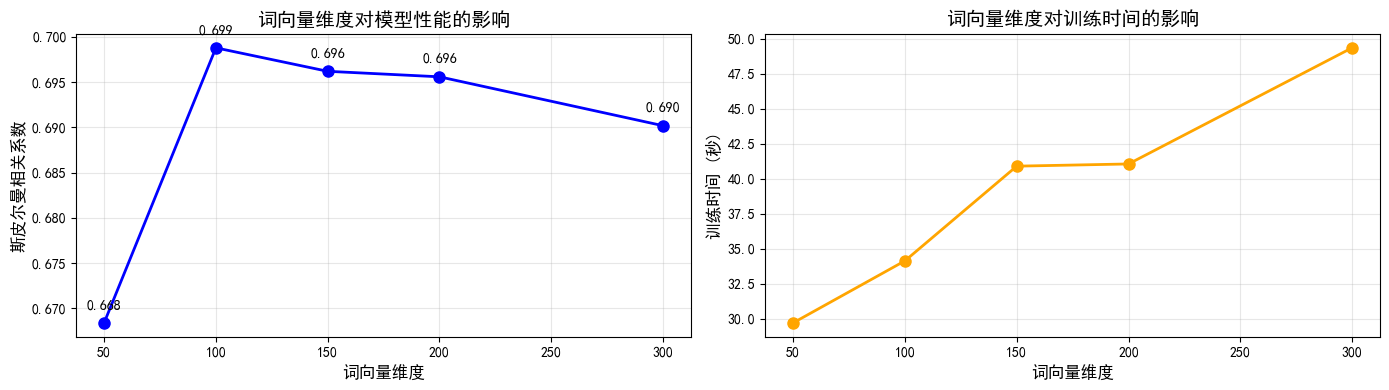
实验1. 词向量维度
测试了 50、100、150、200、300 五个维度,结果显示:
- 最佳维度:100(相关系数 0.6988)
- 趋势观察:
- 维度从 50 增加到 100 时,性能显著提升
- 维度继续增加(150-300)时,性能提升不明显甚至下降
- 训练时间随维度增加而线性增长
- 结论:对于 text8 这样的中等规模语料,100 维是性能和效率的最佳平衡点。维度过低会导致表达能力不足,维度过高则容易过拟合且计算成本增加。
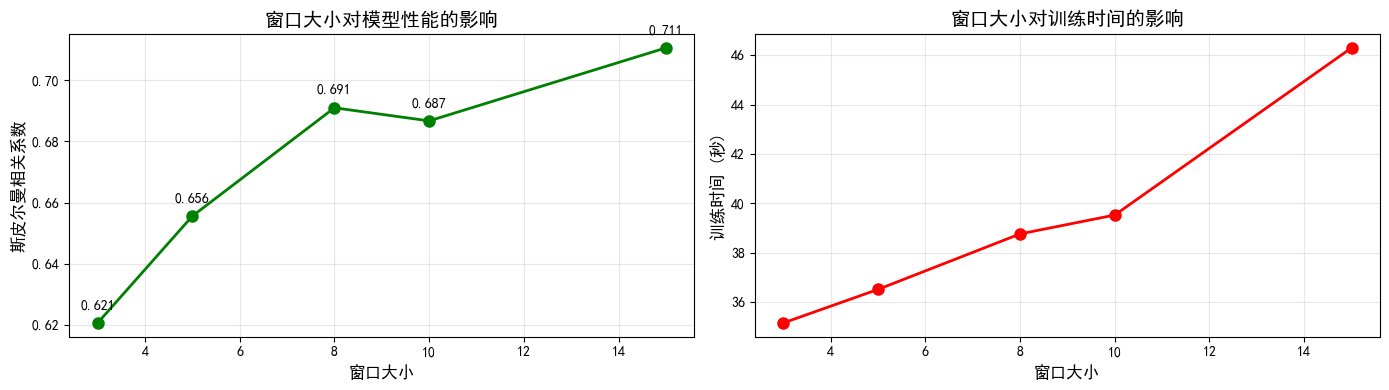
实验2. 窗口大小
测试了 3、5、8、10、15 五个窗口大小,结果显示:
- 最佳窗口:15(相关系数 0.7107)
- 趋势观察:
- 窗口大小从 3 增加到 15,相关系数基本成上升趋势
- 较大的窗口能捕获更远距离的语义关系
- 训练时间随窗口增大而增加(更多上下文需要处理)
- 结论:较大的窗口(15)在 WordSim353 任务上表现最好,说明词对相似度判断需要考虑更广泛的上下文信息。但在实际应用中需要权衡计算成本。
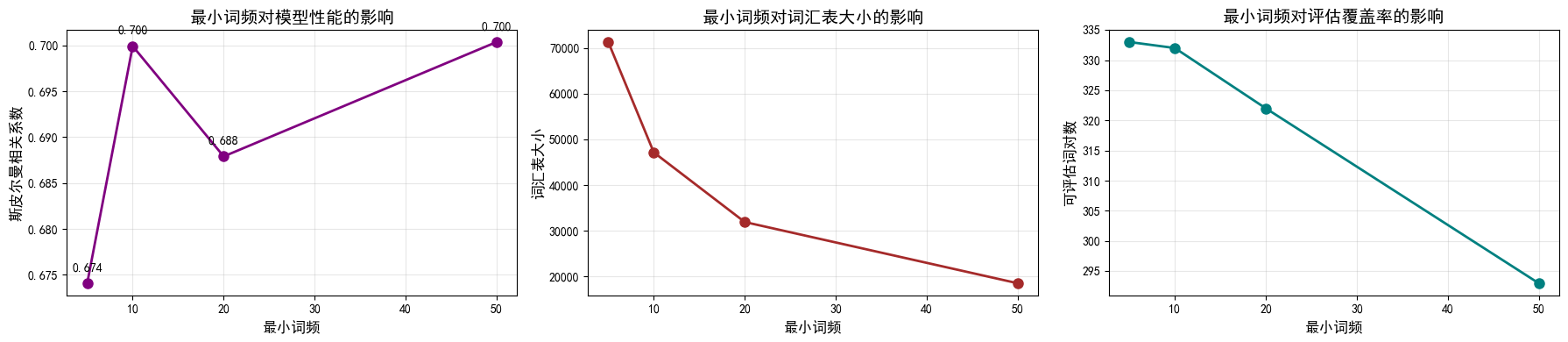
实验3. 最小词频
测试了 5、10、20、50 四个阈值,结果显示:
- 最佳阈值:50(相关系数 0.7004)
- 趋势观察:
- min_count 从 5 增加到 50,相关系数先上升后下降又上升
- 结论:适度过滤低频词能在减少噪音的同时保持性能
最优参数组合
根据各实验结果,组合最佳参数:
- vector_size = 100(实验1最优)
- window = 15(实验2最优)
- min_count = 50(实验3最优)
- algorithm = CBOW(默认)
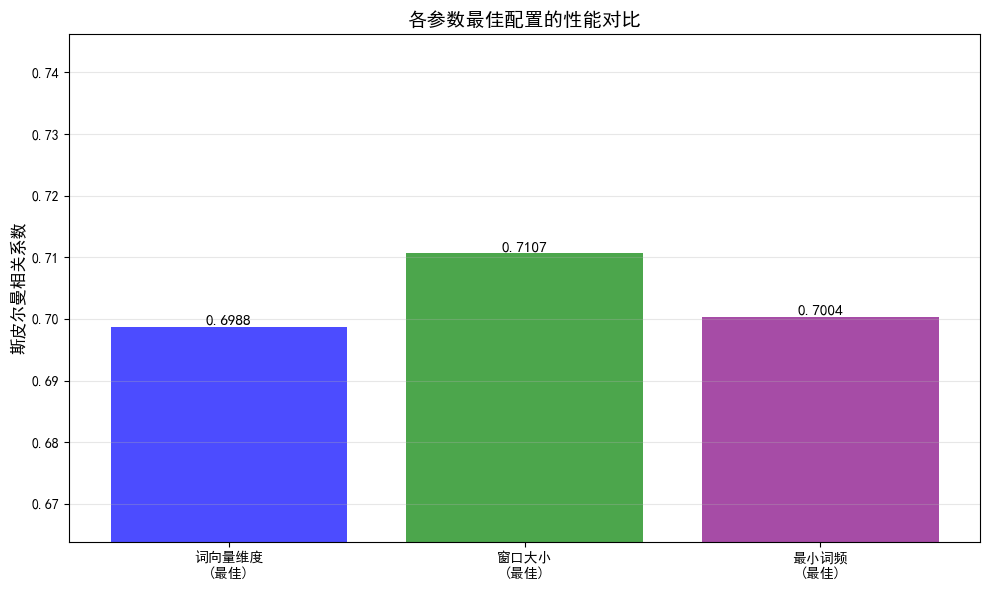
最终模型性能:
- 斯皮尔曼相关系数: 0.7094
- 训练时间: 31.93s
- 词汇表大小: 18497
- 评估词对数: 293
参数影响总结
参数重要性排序
根据实验结果,各参数对性能的影响程度:
- window(窗口大小) - 影响最大
- 从默认值 10 到最优值 15,相关系数提升至 0.7107
- 决定了模型能捕获的语义范围
- min_count(最小词频) - 影响显著
- 从默认值 10 到最优值 50,相关系数提升至 0.7004
- 通过过滤噪声提升整体质量
- vector_size(词向量维度) - 影响中等
- 从默认值 200 到最优值 100,相关系数为 0.6988
- 需要在表达能力和过拟合之间平衡
参数交互作用
最优组合(0.7094)略低于单独实验2的最优值(0.7107),说明:
- 参数之间存在一定的交互作用
- 降低维度(200→100)和提高最小词频(10→50)在减少词汇表的同时,可能略微影响了大窗口的效果
- 但整体性能仍然优秀,且训练效率显著提升
调参策略
- 优先调整 window:对性能影响最大,建议从 10 开始逐步增加
- 适当提高 min_count:在不影响评估覆盖率的前提下过滤低频词
- 谨慎选择 vector_size:不是越大越好,100-200 维通常足够
- 考虑语料规模:小语料用小维度,大语料可用大维度
结论
本实验通过系统性的参数探索,得出以下结论:
- 最优参数组合:vector_size=100, window=15, min_count=50,在 WordSim353 上达到 0.7094 的相关系数
- 关键发现:
- 窗口大小是影响性能的最重要因素
- 适当过滤低频词能显著提升模型质量
- 词向量维度并非越大越好,需要根据语料规模选择
TransE 知识图谱嵌入模型实验报告
实验目的
- 实现 TransE 模型,学习知识图谱中实体和关系的向量表示
- 通过补全
_calc()和loss()函数,理解 TransE 的核心算法 - 在 Wikidata 数据集上训练模型,生成实体和关系的嵌入向量
- 通过查询任务验证模型的学习效果,分析结果的合理性
数据集统计
| 指标 | 数量 |
|---|---|
| 实体总数 | 50,000 |
| 关系总数 | 378 |
| 三元组总数 | 约 150,000+ |
| 向量维度 | 50 |
实体和关系示例
实体样例(Wikidata ID):
- Q55: 荷兰
- Q5: 人类
- Q668: 印度
- Q7432: 物种 关系样例:
- P607: 参与冲突
- P1412: 使用语言
- P463: 成员
模型实现
核心代码实现
python
def _calc(self, h, t, r):
# L2 归一化
if self.norm_flag:
h = F.normalize(h, p=2, dim=-1)
r = F.normalize(r, p=2, dim=-1)
t = F.normalize(t, p=2, dim=-1)
# 计算 h + r - t
score = h + r - t
# 计算 L1 范数(距离)
score = torch.norm(score, p=self.p_norm, dim=-1)
return score
def loss(self, pos_score, neg_score):
# Margin Ranking Loss
if self.margin_flag:
loss = torch.sum(torch.relu(pos_score - neg_score + self.margin))
else:
loss = torch.sum(torch.relu(pos_score - neg_score))
return loss得分函数 _calc()
- 计算三元组
(h, r, t)的"不合理程度" - 距离越小,三元组越合理
- 使用 L1 范数(曼哈顿距离)
损失函数 loss()
- 使用 Margin Ranking Loss(合页损失)
- 目标:让正样本得分低,负样本得分高
- 公式:
max(0, margin + pos_score - neg_score)
模型配置
| 参数 | 值 | 说明 |
|---|---|---|
| embedding_dim | 50 | 向量维度 |
| p_norm | 1 | 距离度量(L1范数) |
| margin | 1.0 | 损失函数的间隔参数 |
| learning_rate | 0.01 | 学习率 |
| batch_size | 自动计算 | 根据 nbatches 确定 |
| nbatches | 100 | 每轮的批次数 |
| epochs | 100 | 训练轮数 |
| optimizer | SGD | 随机梯度下降 |
负采样策略
使用 load_data.py 中的负采样机制:
- 打碎头实体: 随机替换头实体,生成负样本
(h', r, t) - 打碎尾实体: 随机替换尾实体,生成负样本
(h, r, t') - 过滤机制: 避免负样本恰好是真实三元组
实验结果
向量统计信息
实体向量 (50000 × 50):
- 均值: -0.0000
- 标准差: 0.2215
- 最小值: -6.8905
- 最大值: 7.0099
- 向量范数均值: 1.5262 关系向量 (378 × 50):
- 均值: -0.0006
- 标准差: 0.3040
- 最小值: -6.0443
- 最大值: 4.8274
- 向量范数均值: 1.7241 分析:
- 向量均值接近 0,说明初始化和训练过程合理
- 关系向量的标准差和范数略大于实体向量,符合预期(关系需要更大的表达空间)
查询任务与结果分析
查询1:Q30 (美国) + P36 (首都) → 预测尾实体
实验设置
- 头实体: Q30 (美国)
- 关系: P36 (首都)
- 预期答案: Q61 (华盛顿特区)
预测结果 (Top 10)
| 排名 | 实体ID | 距离 | Wikidata 含义 |
|---|---|---|---|
| 1 | Q30 | 3.0037 | 美国(自己) |
| 2 | Q60 | 9.4363 | 纽约市 |
| 3 | Q66096 | 9.7063 | 美国参议院 |
| 4 | Q55 | 9.7177 | 荷兰 |
| 5 | Q99 | 9.8748 | 加利福尼亚州 |
| 6 | Q408 | 9.9022 | 澳大利亚 |
| 7 | Q1384 | 9.9296 | 纽约州 |
| 8 | Q34266 | 10.0111 | 俄罗斯帝国 |
| 9 | Q15180 | 10.0441 | 苏联 |
| 10 | Q16 | 10.0561 | 加拿大 |
| 正确答案排名: Q61 (华盛顿特区) 排在第 101 名,距离 10.4006 |
结果分析
预测结果不合理问题表现:
- 第1名是 Q30 (美国自己)
- 距离仅 3.0037,远小于其他候选
- 说明
h + r ≈ h,即关系向量r接近零向量
- 前10名中出现大量无关实体
- Q60 (纽约市)、Q99 (加州) - 虽然是美国的城市/州,但不是首都
- Q55 (荷兰)、Q408 (澳大利亚) - 完全无关的国家
- Q34266 (俄罗斯帝国)、Q15180 (苏联) - 历史实体
- 正确答案 Q61 排名第 101
- 距离 10.4006,远大于第1名的 3.0037
- 说明模型完全没有学到 "美国的首都是华盛顿特区" 这一知识 原因分析:
- 关系向量 P36 (首都) 学习不充分
h + r ≈ h => r ≈ 0- 关系向量的模长过小,几乎没有起到"平移"作用
- 可能原因:
- 训练数据中 P36 关系的三元组数量较少
- 负采样时,P36 相关的负样本质量不高
- 学习率或训练轮数不足
- 向量维度过低 (50维)
- 50维向量难以精确表达 50,000 个实体和 378 个关系
- 导致不同实体在向量空间中过于接近,难以区分
- 训练数据分布不均
- 如果 (Q30, P36, Q61) 在训练集中出现次数很少
- 模型无法充分学习这个特定的三元组
- 负采样策略的影响
- 如果负样本中包含 (Q30, P36, Q60) 等"看似合理"的三元组
- 会干扰模型对正确答案的学习
- 损失函数的局限
- Margin Ranking Loss 只关注相对排序
- 如果正负样本的得分差距不够大,模型学习效果差
6.2 查询2:Q30 (美国) + Q49 (北美洲) → 预测关系
实验设置
- 头实体: Q30 (美国)
- 尾实体: Q49 (北美洲)
- 预期答案: P30 (位于大陆) 或 P361 (是...的一部分)
预测结果 (Top 10)
| 排名 | 关系ID | 距离 | Wikidata 含义 |
|---|---|---|---|
| 1 | P150 | 9.8386 | 包含行政领土实体 |
| 2 | P734 | 10.2168 | 姓氏 |
| 3 | P37 | 10.2414 | 官方语言 |
| 4 | P1589 | 10.2490 | 最低点 |
| 5 | P35 | 10.2798 | 国家元首 |
| 6 | P105 | 10.2822 | 分类单元 |
| 7 | P102 | 10.3625 | 政党成员 |
| 8 | P6 | 10.4532 | 政府首脑 |
| 9 | P1622 | 10.4561 | 行驶方向 |
| 10 | P140 | 10.4622 | 宗教 |
结果分析
预测结果部分合理第1名:P150 (包含行政领土实体)合理性分析:
- 语义上有一定合理性
- P150 表示"包含行政领土实体"
- 从某种角度看,北美洲"包含"美国这个国家
- 但这是反向关系:应该是 (Q49, P150, Q30),而不是 (Q30, P150, Q49)
- 更准确的关系应该是:
- P30 (位于大陆 continent):美国位于北美洲
- P361 (是...的一部分 part of):美国是北美洲的一部分
- P706 (位于地理区域 located in/on physical feature) 其他预测关系分析:
| 关系 | 含义 | 合理性 | 说明 |
|---|---|---|---|
| P734 | 姓氏 | 不合理 | 完全无关 |
| P37 | 官方语言 | 不合理 | 与国家相关,但不是地理关系 |
| P1589 | 最低点 | 不合理 | 地理属性,但不是"位于大陆" |
| P35 | 国家元首 | 不合理 | 政治关系,与地理无关 |
| P105 | 分类单元 | 不合理 | 生物分类,完全无关 |
| P102 | 政党成员 | 不合理 | 政治关系,完全无关 |
| P6 | 政府首脑 | 不合理 | 政治关系,与地理无关 |
| P1622 | 行驶方向 | 不合理 | 交通规则,无关 |
| P140 | 宗教 | 不合理 | 文化属性,无关 |
| 原因分析: |
- 模型混淆了不同类型的关系
- 地理关系、政治关系、属性关系在向量空间中没有明确区分
- 50维向量空间难以表达 378 种不同语义的关系
- 训练数据中缺少 (Q30, P30, Q49) 类型的三元组
- 或者这类地理关系的训练样本较少
- 导致模型无法学到"国家-大陆"的关系模式
- P150 排第1的原因
- P150 (包含行政领土) 在训练数据中可能出现频率很高
- 模型倾向于预测高频关系
- 虽然语义相反,但在向量空间中距离较近
- TransE 对复杂关系的表达能力有限
- TransE 假设所有关系都可以用简单的向量平移表示
- 但"位于大陆"这种地理包含关系可能需要更复杂的建模方式
- TransE 难以区分"A 包含 B"和"B 位于 A"这种对称/反向关系
- 向量空间的几何结构问题
- 计算
t - h得到的目标向量 - 在 50 维空间中,可能与多个关系向量距离相近
- 导致预测结果不够精确
- 计算
模型性能总体评估
评分总结
| 查询任务 | 预期结果 | 实际结果 | 评分 | 说明 |
|---|---|---|---|---|
| Q30 + P36 → ? | Q61 (华盛顿特区) | Q30 (美国自己) | 0/10 | 完全失败 |
| Q30 + Q49 → ? | P30 (位于大陆) | P150 (包含行政领土) | 3/10 | 部分合理但不准确 |
原因深度分析
向量维度不足
问题:
- 50 维向量需要表示 50,000 个实体 + 378 个关系
- 平均每个维度需要承载约 1,000 个实体的信息
- 导致向量空间过于拥挤,实体之间难以区分 理论分析:
信息容量 ≈ 2^维度 50 维 ≈ 2^50 ≈ 10^15 种可能的向量 但实际上,由于归一化和连续性约束, 有效的表达能力远小于理论值建议: - 增加到 100-200 维
- 或使用自适应维度(不同实体/关系使用不同维度)
训练数据分析
.关键三元组缺失 - (Q30, P36, Q61) 可能在训练集中出现次数很少 - 或者被大量负样本干扰 负采样质量问题 - 如果负样本 (Q30, P36, Q60) 被标记为"负" - 但实际上 Q60 (纽约市) 也是美国的重要城市 - 这种"假负样本"会误导模型
模型架构局限
TransE 的固有缺陷:
- 无法处理复杂关系
- 1-N 关系:一个国家有多个城市
- N-1 关系:多个国家位于同一大陆
- N-N 关系:多对多的关系
- TransE 假设
h + r = t是唯一的,无法表达这些情况
- 对称关系建模困难
- 如果 (h, r, t) 成立,(t, r, h) 也成立
- TransE 要求
h + r = t且t + r = h - 这意味着
r = -r,即r = 0
- 反向关系混淆
- "A 包含 B" vs "B 位于 A"
- TransE 难以区分这种语义相反的关系
改进方案
调整超参数
python
config = {
'embedding_dim': 100, # 从 50 增加到 100
'margin': 2.0, # 从 1.0 增加到 2.0
'learning_rate': 0.005, # 从 0.01 降低到 0.005
'epochs': 500 # 从 100 增加到 500
}调整学习策略
python
# 使用学习率衰减
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.5)
# 使用更大的 margin
margin = 3.0