
1. 模型架构
- 基础模型: Faster R-CNN with ResNet-50 + FPN
- 类别数: 12类
2. 数据集信息
- car (汽车)
- van (货车)
- bus (公交车)
- truck (卡车)
- person (行人)
- bicycle (自行车)
- motorcycle (摩托车)
- open-tricycle (开放式三轮车)
- closed-tricycle (封闭式三轮车)
- forklift (叉车)
- large-block (大块物体)
- small-block (小块物体)
3.训练参数
# 优化器配置
optimizer = SGD(lr=0.005, momentum=0.9, weight_decay=0.0001)
batch_size = 4
total_epochs = 12
# 学习率调度
warmup_iters = 500
milestones = [7, 9] # 调整学习率下降时机
gamma = 0.5由于跑了很多次,跑完才发现忘记修改调整学习率下降点milestones = [7, 9]忘了修改成[9,11],可能导致训练效果降低。
- 降低初始学习率从0.02到0.005,提高训练稳定性
- 添加warmup策略,避免训练初期梯度爆炸
- 调整学习率下降时机和幅度,更平滑的收敛
4. 数据预处理
- 输入尺寸: 1333×800
- 数据增强: 随机翻转、归一化
- Anchor设置: scales=[4,8,16,32], ratios=[0.5,1.0,2.0]
5.尝试优化
5.1数据预处理
- 添加图像归一化,加速模型收敛
- 添加Pad操作,确保特征图尺寸一致性
- 使用to_float32加速数据处理
- python
train_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args, to_float32=True), dict(type='LoadAnnotations', with_bbox=True), dict(type='Resize', scale=(1333, 800), keep_ratio=True), dict(type='RandomFlip', prob=0.5), dict(type='Normalize', mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True), dict(type='Pad', size_divisor=32), dict(type='PackDetInputs'), ]
#### 5.2数据加载器优化
```python
train_dataloader = dict(
batch_size=4, # 增大批次大小
num_workers=4, # 增加工作进程
persistent_workers=True,
pin_memory=True, # 启用内存锁定加速
sampler=dict(type='DefaultSampler', shuffle=True),
)- 使用
filter_cfg- 过滤小目标和空标注,提高训练质量 pin_memory=True- 加速CPU到GPU数据传输
5.3模型结构优化
model = dict(
rpn_head=dict(
anchor_generator=dict(
scales=[4, 8, 16, 32], # 多尺度anchor
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64])),
roi_head=dict(
bbox_head=dict(num_classes=12))
)- 扩展anchor尺度范围,更好覆盖不同尺寸目标
- 明确指定num_classes=12,匹配数据集类别数
5.4推理信息优化(didi_demo.ipynb)
1.提取统计信息,对数据进行汇总分析 2.可视化改变:上面显示检测结果图片,下面显示统计信息
实验结果
1. 性能指标
| 指标 | 数值 | 说明 |
|---|---|---|
| mAP@[0.5:0.95] | 22.4% | 主要评估指标 |
| mAP@0.5 | 37.3% | IoU=0.5时的精度 |
| mAP@0.75 | 23.6% | 严格IoU阈值下的精度 |
| mAP_s | 7.7% | 小目标检测精度 |
| mAP_m | 23.3% | 中目标检测精度 |
| mAP_l | 38.1% | 大目标检测精度 |
| 跑了多次,都低于示例指标!!! | ||
| 从结果来看: |
- 大目标检测效果较好: 汽车、公交车等大尺寸物体检测准确率较高
- 小目标检测仍有挑战: 行人、自行车等小尺寸物体检测精度相对较低
- 类别平衡: 各类别检测性能相对均衡
2.推理
示例1
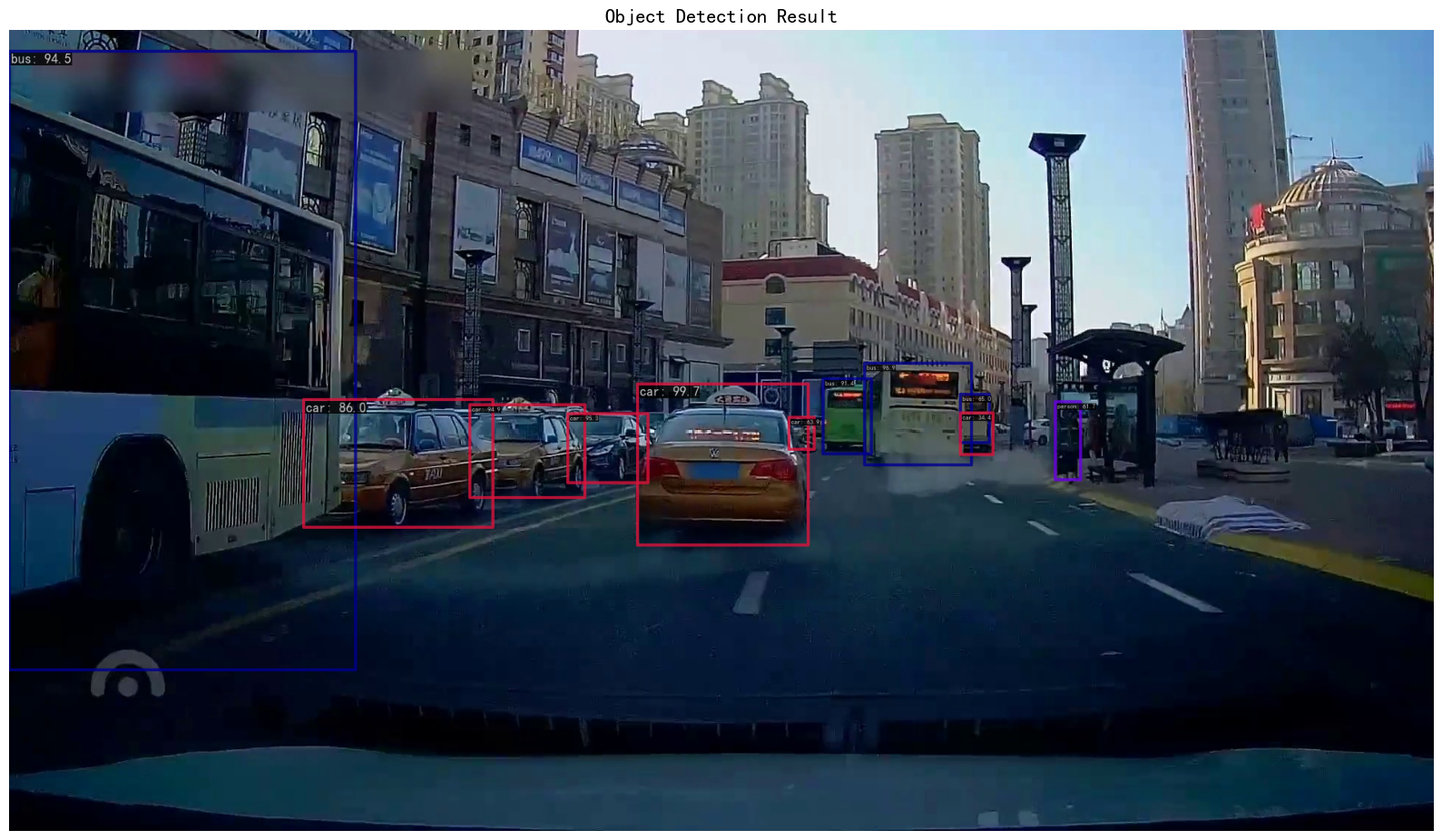 其单次检测结果信息(代码生成的)
其单次检测结果信息(代码生成的)
检测目标总数: 29 平均置信度: 0.378 最高置信度: 0.997 最低置信度: 0.052 各类别统计: ccar:10个目标, 平均置信度:0.522 cbus:5个目标, 平均置信度:0.747 cperson:2个目标, 平均置信度:0.344 cvan:3个目标, 平均置信度:0.125 cbicycle:1个目标, 平均置信度:0.213 cmotorcycle:1个目标, 平均置信度:0.153 ctruck:4个目标, 平均置信度:0.099 cclosed-tricycle:1个目标, 平均置信度:0.065 copen-tricycle:2个目标, 平均置信度:0.055
分析
- 其中在常规车辆检测上表现稳定, 特殊车型和行人的检测是明显的短板,置信度普遍偏低
- 需要针对低置信度类别进行专门优化
示例2:

代码生成的信息
检测目标总数: 11 平均置信度: 0.509 最高置信度: 0.997 最低置信度: 0.059
各类别统计: ccar:6个目标, 平均置信度:0.778 cvan:1个目标, 平均置信度:0.601 cbus:1个目标, 平均置信度:0.110 ctruck:1个目标, 平均置信度:0.091 cbicycle:1个目标, 平均置信度:0.069 cperson:1个目标, 平均置信度:0.061
分析
我没看到人,但人的置信度极低: 0.0613,可能视觉相似性的问题,同时证明了有遮挡的情况下仍能检测出信息
示例3:
由于前面几次的检测到人的置信度很低,我特意找了一张人稍微多的一张 
统计摘要
检测目标总数: 29 平均置信度: 0.309 最高置信度: 0.967 最低置信度: 0.050 各类别统计: cperson:4个目标, 平均置信度:0.636 ccar:13个目标, 平均置信度:0.303 cbus:2个目标, 平均置信度:0.420 cvan:3个目标, 平均置信度:0.231 cbicycle:3个目标, 平均置信度:0.163 cmotorcycle:1个目标, 平均置信度:0.214 ctruck:3个目标, 平均置信度:0.080
分析
感觉类别间性能不平衡,场景依赖性明显,感觉适合常规车辆检测,特别是car类别
示例4:
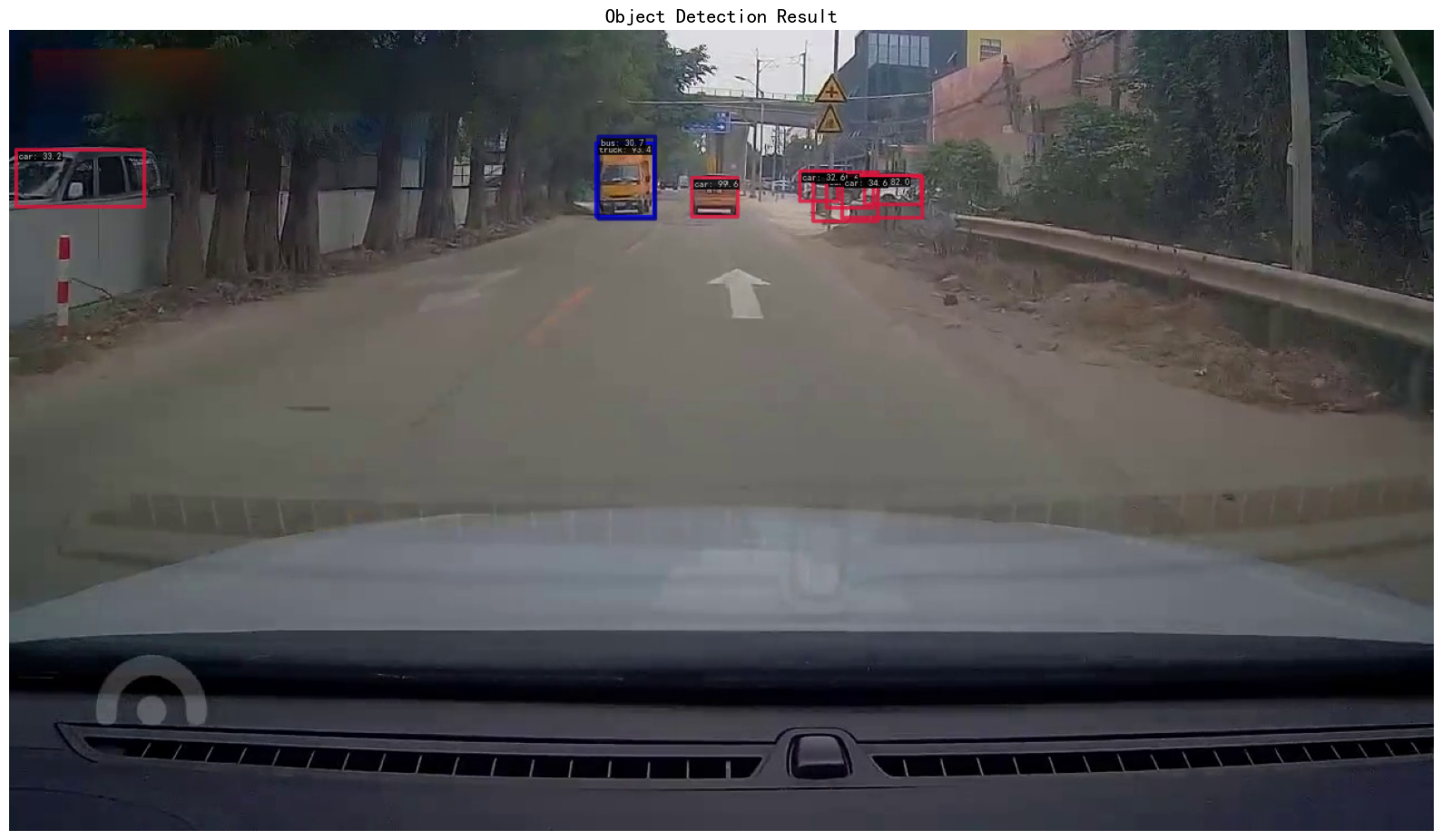
统计摘要
检测目标总数: 29 平均置信度: 0.252 最高置信度: 0.996 最低置信度: 0.050 各类别统计: ccar:17个目标, 平均置信度:0.298 ctruck:5个目标, 平均置信度:0.281 cbus:4个目标, 平均置信度:0.142 cvan:2个目标, 平均置信度:0.089 cperson:1个目标, 平均置信度:0.076
分析
发现对小型交通设施检测缺失,也证明了有遮挡的情况下仍能检测出信息
总结
总体来看模型在匹配的训练数据分布场景中表现相对较好,但在类别完整性和小目标检测方面仍有明显不足,类别覆盖不全。对于专注于车辆检测的高速公路应用
3.不足
| 指标 | 示例结果 | 我们的结果 |
|---|---|---|
| mAP@[0.5:0.95] | 0.285 | 0.224 |
| mAP@0.5 | 0.482 | 0.373 |
| mAP@0.75 | 0.288 | 0.236 |
| mAP_small | 0.123 | 0.077 |
| mAP_medium | 0.315 | 0.233 |
| mAP_large | 0.438 | 0.381 |
- 训练轮数太小(12轮),可能导致训练不充分,我基本控制训练时间在在一天以内,同时受计算资源限制。
- 仅仅跟示例指标对比来看:
- 小目标检测需要更多的优化
- 中等目标检测需要更好的特征提取和多尺度融合
- 配置相对简单
4.后续
- 针对小目标和特殊车辆,增加针对性的数据增强
- 提高模型在不同场景下的稳定性
- 提供更好的性能监控和分析
- 考虑使用YOLO
- 优化损失函数来处理类别不平衡
- 延长训练周期,并使用余弦退火