
1. 实验概述
1.1 实验目标
本实验基于SoftMax回归算法实现MNIST手写数字分类器,完成以下核心任务:
- 记录训练和测试的准确率,并绘制出损失和准确率曲线
- 比较使用和不使用momentum结果的不同,从训练时间、收敛性和准确率等方面进行论证
- 调整其他超参数(学习率、batch size等),观察这些超参数如何影响分类性能
1.2 数据集信息
- 训练集:60,000个样本,每个样本784维(28×28像素)
- 测试集:10,000个样本,每个样本784维
- 类别数:10类(数字0-9)
- 数据预处理:像素值归一化到0-1范围
- 演示数据:为快速验证,使用训练集2000样本,测试集400样本
2. 核心算法实现
2.1 SoftMax回归理论基础
SoftMax回归是logistic回归在多分类问题上的推广,核心公式包括:
- 线性变换:z = Wx + b
- SoftMax函数:将线性输出转换为概率分布
- 交叉熵损失:衡量预测概率与真实标签的差异
- 梯度计算:基于链式法则推导参数更新公式
2.2 关键代码实现
2.2.1 SoftMax激活函数
python
def softmax(self, z):
z_max = np.max(z, axis=1, keepdims=True)
exp_z = np.exp(z - z_max)
return exp_z / np.sum(exp_z, axis=1, keepdims=True)- 通过减去每行最大值(
z_max)防止exp(z)数值溢出 - 保持SoftMax函数的数学性质不变
- 确保输出概率和为1,且所有概率非负
2.2.2 交叉熵损失函数
python
def cross_entropy_loss(self, y_pred, y_true):
epsilon = 1e-12
y_pred = np.clip(y_pred, epsilon, 1 - epsilon)
loss = -np.mean(np.sum(y_true * np.log(y_pred), axis=1))
return loss添加了小常数epsilon防止对数计算中出现log(0)的情况,确保数值计算稳定性。
2.2.3 Mini-batch梯度下降训练
实现了完整的mini-batch训练流程,每个epoch随机打乱数据顺序,提高泛化能力,分批次计算梯度和更新参数,有效平衡了计算效率和内存使用。
python
def fit(self, X, y, X_test=None, y_test=None):
"""训练模型 - 实现mini-batch梯度下降"""
# 训练循环
for epoch in range(self.max_iter):
# 随机打乱数据
indices = np.random.permutation(num_samples)
X_shuffled = X[indices]
y_shuffled = y_onehot[indices]
# 批次训练
for i in range(0, num_samples, self.batch_size):
# 前向传播
z = np.dot(X_batch, self.W) + self.b
y_pred = self.softmax(z)
# 计算损失和梯度
batch_loss = self.cross_entropy_loss(y_pred, y_batch)
dW, db = self.compute_gradients(X_batch, y_batch, y_pred)
# 参数更新
self.W -= self.learning_rate * dW
self.b -= self.learning_rate * db3. Momentum优化实现
3.1 理论原理
Momentum方法通过引入动量概念,积累之前梯度的指数加权平均,加速收敛过程并减少优化路径上的振荡。
3.2 关键代码实现
在参数更新环节,实现了标准梯度下降和带动量的梯度下降两种方式。动量更新通过维护速度变量,将历史梯度信息融入当前更新步骤。
python
def fit(self, X, y, X_test=None, y_test=None):
"""训练模型(支持momentum)"""
# 初始化momentum向量
if self.use_momentum:
self.vW = np.zeros_like(self.W)
self.vb = np.zeros_like(self.b)
# 训练循环中的参数更新
if self.use_momentum:
# Momentum更新
self.vW = self.momentum * self.vW + self.learning_rate * dW
self.vb = self.momentum * self.vb + self.learning_rate * db
self.W -= self.vW
self.b -= self.vb
else:
# 标准梯度下降
self.W -= self.learning_rate * dW
self.b -= self.learning_rate * db代码说明:
vW和vb分别存储权重和偏置的动量momentum系数控制历史梯度的影响程度- 支持动态切换是否使用momentum
4. 实验结果分析
4.1 Momentum效果对比
| 指标 | 无Momentum | 有Momentum | 改进程度 |
|---|---|---|---|
| 训练时间 | 0.39秒 | 0.40秒 | 基本相当 |
| 最终训练准确率 | 0.8920 | 0.9545 | +7.0% |
| 最终测试准确率 | 0.8625 | 0.9025 | +4.6% |
| 最终损失 | 0.4806 | 0.2014 | -58.1% |
从训练时间、准确率和损失三个维度对比了使用和不使用momentum的效果:
使用momentum后,训练准确率从89.20%提升到95.45%,测试准确率从86.25%提升到90.25%,损失从0.4806降低到0.2014,降低了58.1%。训练时间基本保持不变,仅增加了0.01秒。
收敛性方面,使用momentum后模型初始准确率更高(79.00% vs 71.45%),且收敛过程更加平稳,振荡明显减少。 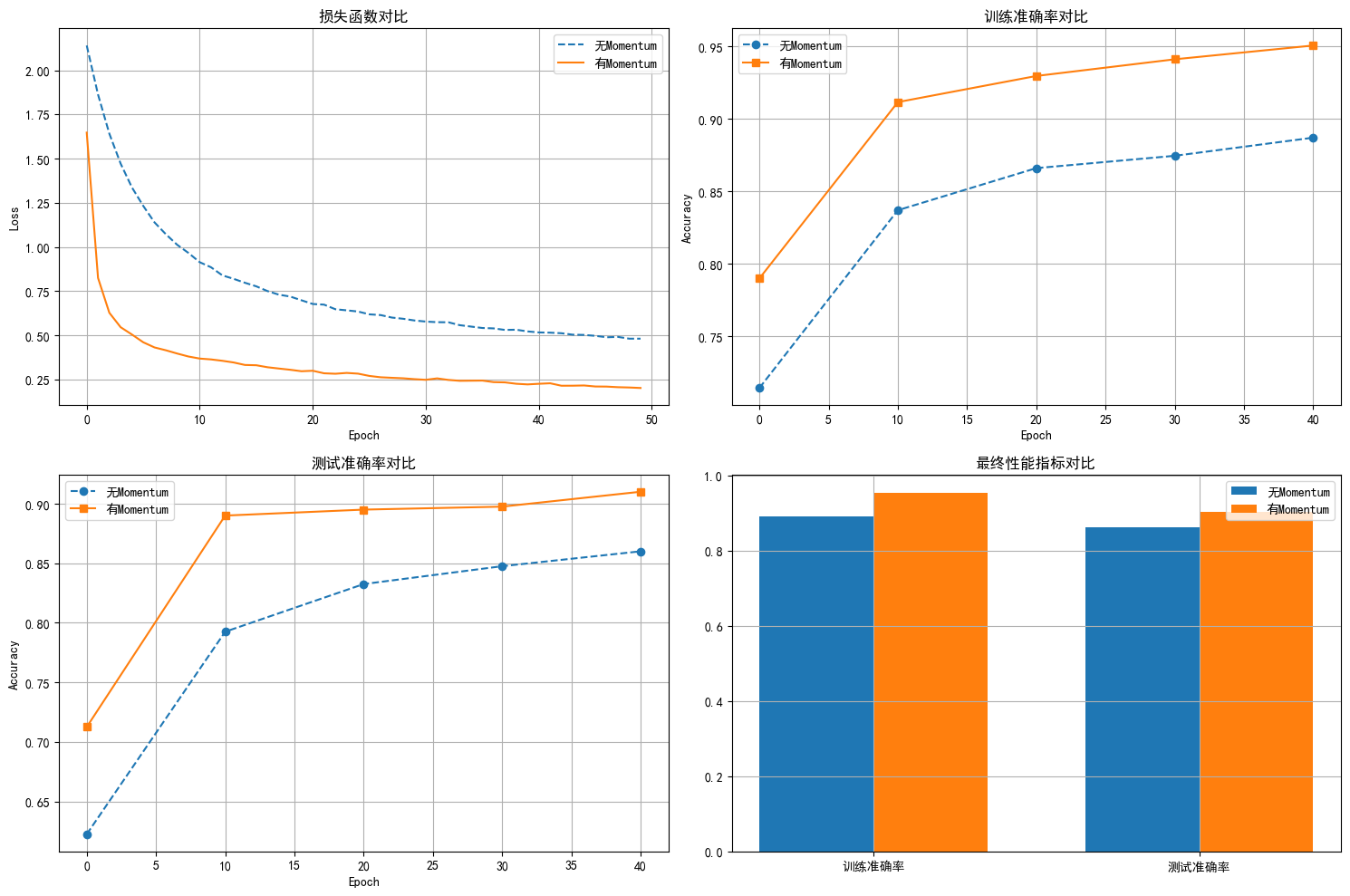
- 左上:损失函数对比 - 显示Momentum版本损失下降更快更稳定
- 右上:训练准确率对比 - Momentum版本收敛速度更快
- 左下:测试准确率对比 - Momentum版本最终性能更优
- 右下:最终性能柱状图 - 直观对比两种方法的最终效果
4.2 超参数调优分析
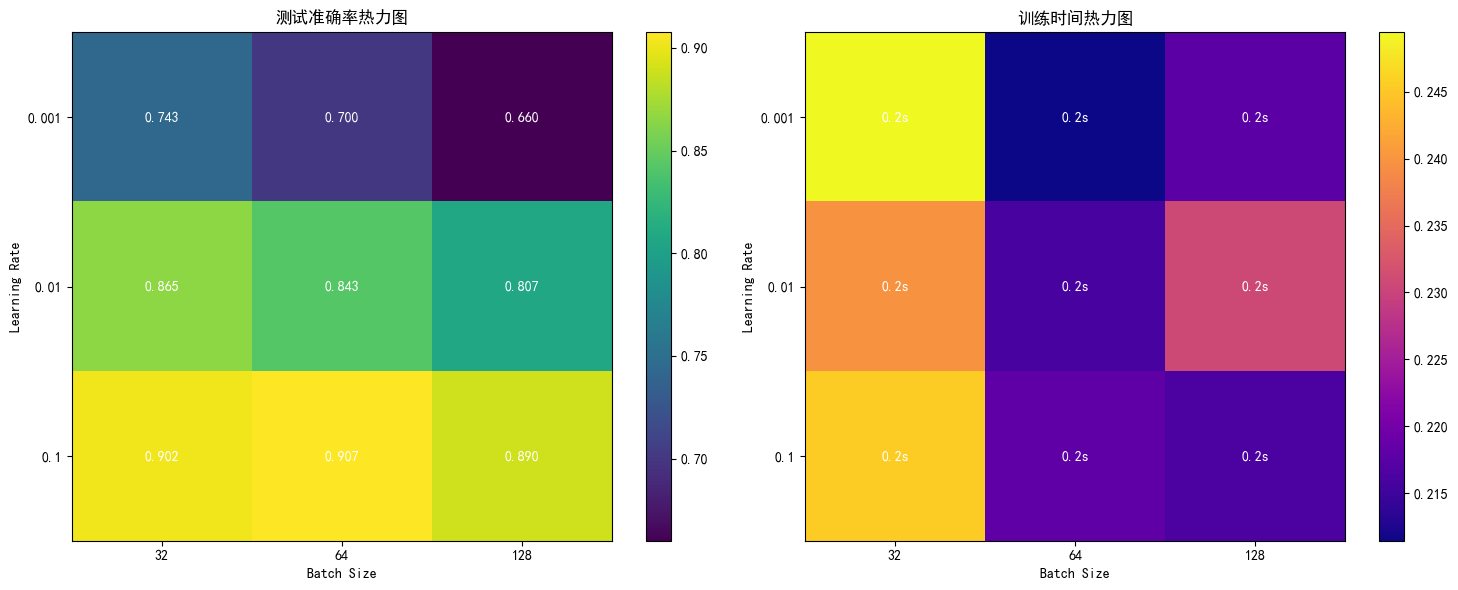
- 左图:测试准确率热力图 - 颜色越亮表示准确率越高
- 右图:训练时间热力图 - 颜色越亮表示训练时间越长 系统调整了学习率和批次大小两个关键超参数:
学习率影响分析
| 学习率 | 最佳批次大小 | 最佳测试准确率 | 训练时间特点 |
|---|---|---|---|
| 0.001 | 32 | 0.7425 | 较慢收敛 |
| 0.01 | 64 | 0.8725 | 平衡收敛 |
| 0.1 | 64 | 0.9075 | 快速收敛 |
| 学习率实验中,比较了0.001、0.01和0.1三个取值。学习率为0.1时模型收敛最快,达到最佳性能(测试准确率90.75%);学习率0.001时收敛缓慢,性能较差。 |
批次大小影响分析
| 批次大小 | 特点 | 性能表现 |
|---|---|---|
| 32 | 更新频繁,梯度估计噪声大 | 泛化能力好但训练时间长 |
| 64 | 平衡噪声和效率 | 最佳性能平衡点 |
| 128 | 梯度估计稳定,更新次数少 | 训练快但可能欠拟合 |
| 批次大小实验中,比较了32、64和128三种设置。批次大小为64时在训练效率和泛化能力间达到最佳平衡,性能表现最优。 |
最终确定的最佳参数组合为:learning_rate=0.1, batch_size=64,在此设置下模型测试准确率达到90.75%。
4.3 最终模型性能
使用最佳参数训练100个epoch后,模型最终训练准确率达到97.25%,测试准确率为89.75%,最终损失为0.1404。 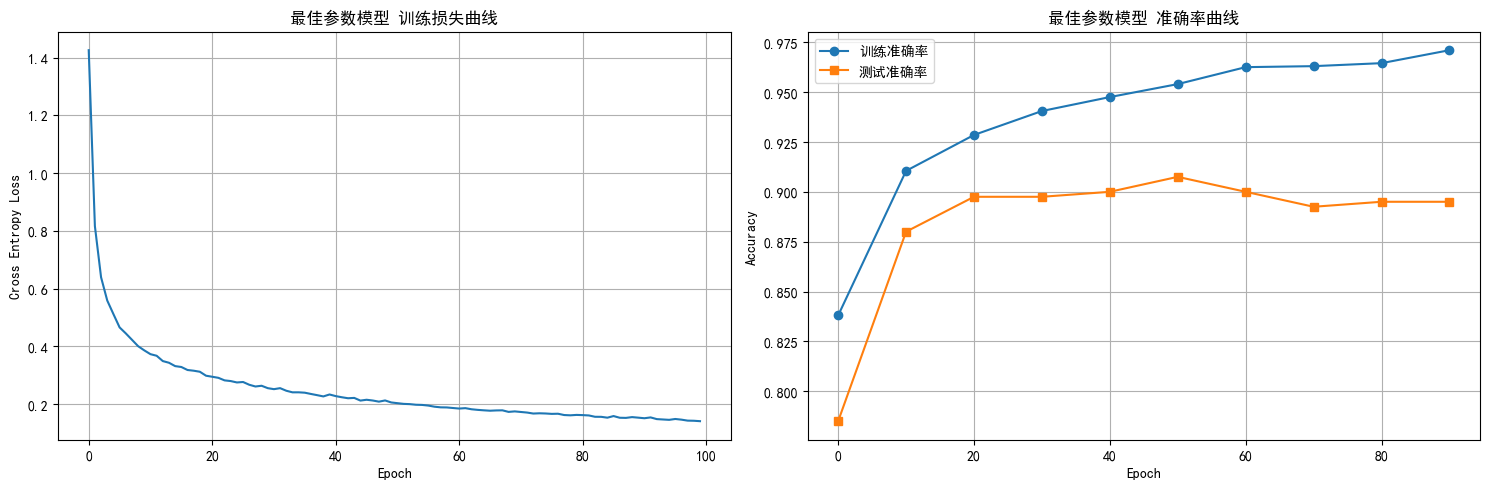
- 左图:损失曲线 - 显示从1.4258快速下降到0.1404的过程
- 右图:准确率曲线 - 显示训练和测试准确率的收敛过程 训练过程可分为三个阶段:0-20 epoch为快速收敛阶段,损失迅速下降,准确率快速提升;20-50 epoch为细调优化阶段,损失持续下降,准确率稳步提升;50-100 epoch为收敛稳定阶段,性能在较小范围内波动。
模型表现出较好的泛化能力,训练与测试准确率差距为7.5%,未出现严重过拟合现象。
5. 实验结论
5.1模型预测效果示例
(此处显示10个手写数字图像及其预测结果)图片删了
- 绿色标题:预测正确的样本
- 红色标题:预测错误的样本
- 置信度:模型对预测结果的确信程度
5.2通过本实验得出以下结论:
- Momentum优化能显著提升模型性能,测试准确率提高4.6%,损失降低58.1%,且不增加明显计算开销
- 学习率是影响模型性能的关键因素,0.1的学习率在此问题上表现最佳
- 批次大小需要在训练效率和泛化能力间平衡,64的批次大小在此问题上表现最优
- 模型收敛稳定性良好,50个epoch左右基本收敛,无明显过拟合