
深度学习基本概念
实验报告无图片!实验报告无图片!实验报告无图片!
一、到底啥是深度学习?
简单说:就是让机器像人脑一样"层层思考"的智能工具。
专业点:
- 狭义:特指人工神经网络(像人脑神经元的计算网络),包括:
- 多层感知机(MLP):基础款神经网络
- 卷积神经网络(CNN):专攻图像识别(👉 比如认猫狗)
- 循环神经网络(RNN):处理序列数据(👉 比如语音翻译)
- 广义:任何层次化的机器学习模型(数据要经过多层加工),例如:
- 深度信念网络(DBN)
- 稀疏HMAX模型(仿视觉皮层结构)
💡 关键比喻:
想象剥洋葱——浅层模型只能剥1-2层(只能看轮廓),深度学习能剥10层+(看到纹理、细节、本质)。
二、为啥非要"深度"?
核心原因:现实数据太复杂!
- 一张图片包含百万像素(高维度)
- 其中隐藏的结构(比如猫耳朵的轮廓)简单模型根本抓不住
Geoffrey Hinton老爷子总结:
- 浅层模型需要额外计算模块补漏洞 → 费劲
- 深度网络用更简洁的结构解决复杂问题 → 高效
📈 实例:ImageNet大赛中,152层的ResNet(2015)错误率仅3.6%,而8层浅模型错误率高达25.8%!
三、和AI、机器学习啥关系?
用个套娃图解释:
人工智能(AI)
└─ 机器学习(ML)
└─ 深度学习(DL)- AI:最广(比如知识库系统)
- ML:教机器从数据学习(比如SVM分类器)
- DL:ML的子集,靠多层神经网络自动学特征
✅ 关键差异:
传统机器学习要人工设计特征(比如告诉机器"猫耳朵是三角形"),而深度学习直接喂原始数据,机器自己学出"猫耳朵"特征!
四、神经网络的"老祖宗"
虽然不讲历史,但理解概念需知两个基石模型:
McCulloch-Pitts神经元(1943)
- 简化版脑细胞:输入→加权求和→阶跃函数输出(0或1)
- 数学表示:
- 局限:只能处理单调逻辑(无法直接实现"非"操作)
感知机(Perceptron, 1958)
- 加了权重学习!首次用误差更新参数:
- 重大意义:线性分类器鼻祖(但只能解决线性问题,比如AND/OR)
- 加了权重学习!首次用误差更新参数:
五、深度学习的"必杀技"
自动特征提取
- 传统方法:人工设计特征 → 累死人且不通用
- 深度学习:原始数据输入 → 网络逐层抽象特征
例如识别人脸:
第一层学边缘 → 第二层学五官 → 第三层拼出整张脸
层次化表示
- 像大脑视觉通路:视网膜→LGN→皮层...
- 每层对信息分级加工,底层学简单模式,高层组合复杂概念
六、举个生活化的例子 🌰
任务:教机器认"咖啡杯"
- 传统方法:
手动告诉机器:"杯口是圆的,有手柄,高度10cm..." → 规则一改全完蛋 - 深度学习:
- 灌入10万张杯子的图片
- 网络第一层发现"弧形边缘"
- 第二层拼出"圆形轮廓+长条物体"
- 第三层组合成"杯口+杯身+手柄"
- 输出:"咖啡杯!概率98%"
🔥 效果:
换角度、加奶泡、手柄残缺...照样能认!
关键总结
| 概念 | 大白话解释 | 技术核心 |
|---|---|---|
| 深度学习本质 | 机器"脑补"数据的多层理解能力 | 层次化特征提取 |
| "深度"重要性 | 复杂问题必须层层拆解(浅层搞不定) | 网络深度 vs 数据复杂度 |
| 与传统ML区别 | 机器自己学特征 vs 人工设计特征 | 端到端学习(End-to-End) |
| 神经元基础 | 输入加权求和 → 非线性激活 → 输出 | 阶跃函数/Sigmoid/ReLU |
💎 一句话精髓:
深度学习 = 堆叠多层的神经网络 + 自动特征学习 + 处理复杂数据的能力
深度学习的发展历程
一、史前时代(1943-1960s):神经元的诞生
1943年:McCulloch-Pitts神经元模型
- 核心:用数学模拟生物神经元(输入加权求和 → 阶跃函数输出)
- 意义:首次证明神经网络可执行逻辑运算(AND/OR),但无法处理"非"操作(单调性限制)。
- 幕后故事:
- 皮茨(贫民窟天才)与麦卡洛克(精英医生)合作,论文被冯·诺依曼用作计算机设计基础。
- 维纳控制论小组的破裂(因谣言)导致皮茨抑郁而终,研究中断。
阈值逻辑单元 - 神经元的数学“灵魂”
大白话解释: 想象一个投票委员会,要决定是否通过一个提案。
- 每个委员(输入信号 )的发言权不一样(权重 )。
- 有的委员是支持派(兴奋性输入),有的是反对派(抑制性输入)。
- 委员会有一个硬性规定(阈值 ):只有总支持票的权重达到或超过这个数,提案才通过(输出1),否则就否决(输出0)。
理论核心: 它就是最早的人工神经元数学模型,是所有神经网络的基础。其核心是一个阶跃函数:
图解(来自讲义):
x₁ (兴奋性) ---\
x₂ (兴奋性) ---\
∑ ---> 与阈值θ比较 ---> y (输出 0 或 1)
z₁ (抑制性) ---/
z₂ (抑制性) ---/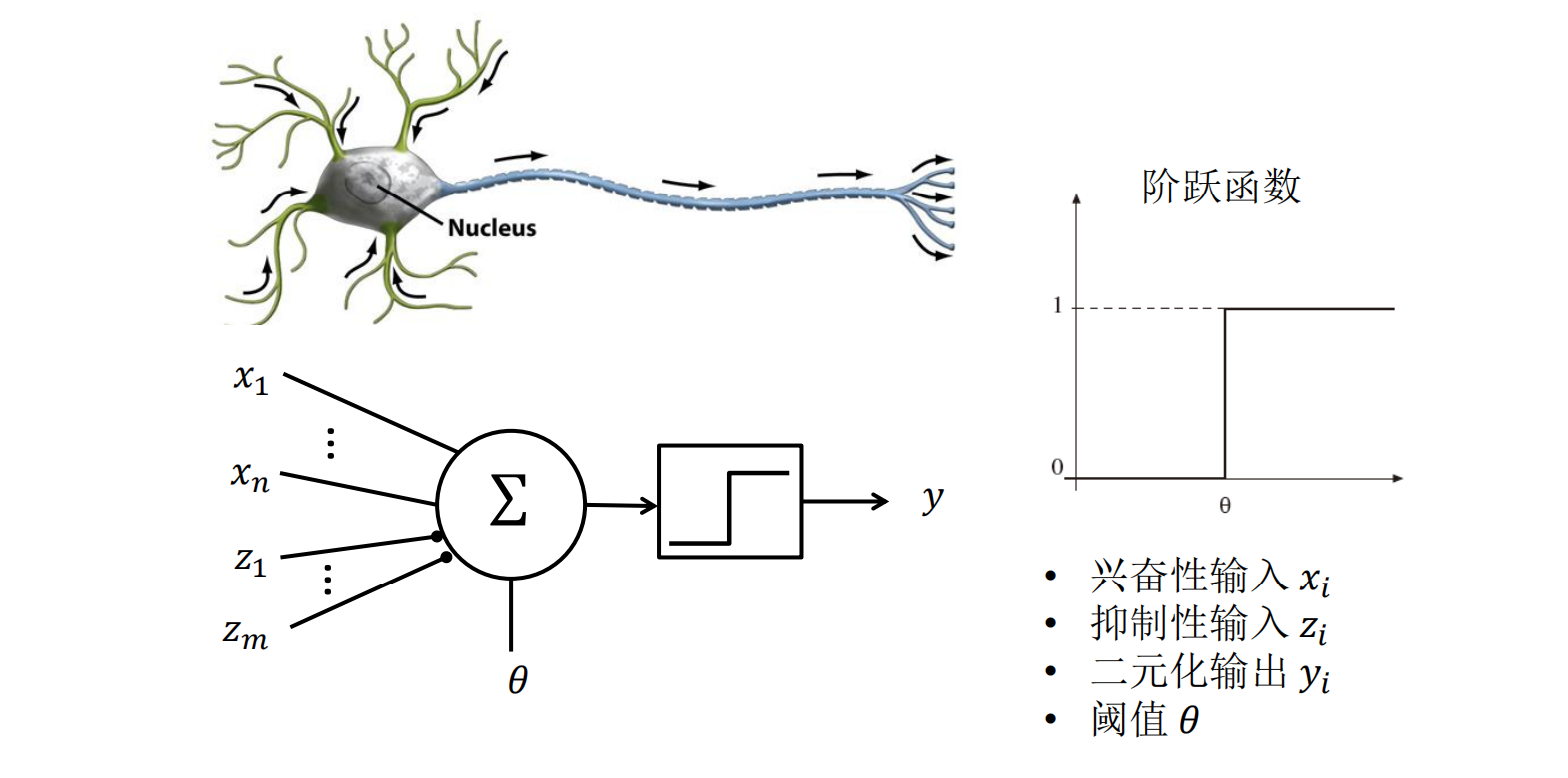 暂且了解一下:
暂且了解一下:
- 兴奋性输入 (Excitatory Inputs)
作用:鼓励或促进神经元激活。它们的作用是让神经元的输出趋向于 1。
工作原理:
每个输入 (x₁, x₂, ... xₙ) 都对应一个权重 (w₁, w₂, ... wₙ)。
如果某个输入是兴奋性的,则其权重为正数 (
w > 0)。这个正的权重会乘以输入值(通常是0或1),得到一个正的值,贡献给神经元的净输入(加权和)。
类比:就像是一个加速踏板,踩得越深(输入值越大或权重越大),车跑得越快(神经元越容易激活)。
- 抑制性输入 (Inhibitory Inputs)
作用:阻止或抑制神经元激活。它们的作用是让神经元的输出趋向于 0。
工作原理:
如果某个输入是抑制性的,则其权重为负数 (
w < 0)。这个负的权重会乘以输入值,得到一个负的值,从神经元的净输入中“减去”一部分,使其更难以达到激活阈值。
抑制性输入通常拥有一票否决权,只要有一个为1,输出就强制为0。
类比:就像是一个刹车踏板,踩得越深(输入值越大或权重绝对值越大),车越难加速(神经元越难激活)。
McCulloch-Pitts (M-P) 单元 - TLU的“硬核”特化
大白话解释: 这是TLU的一个具体实现,非常死板和严格,就像是一个只有开关、没有音量旋钮的电路。
- 规则极简:
- 一票否决制:任何一个抑制性输入()为1,立刻关机,输出0。
- 投票表决:如果没有抑制信号,就把所有兴奋性输入()加起来(相当于每个输入的权重 )。
- 阈值决定:总和 就开机(输出1),否则关机(输出0)。
理论核心: 它用最简单的规则证明了神经网络可以执行逻辑计算。它是计算机和人工智能理论的基石之一。
数学表达:
举个例子(实现逻辑AND):
- 设两个兴奋性输入 , (取值0或1),无抑制输入。
- 设阈值 。
- 计算结果:
- -> sum=0 (<2) -> y=0
- -> sum=1 (<2) -> y=0
- -> sum=1 (<2) -> y=0
- -> sum=2 (>=2) -> y=1
- 看,这就是一个完美的与门!
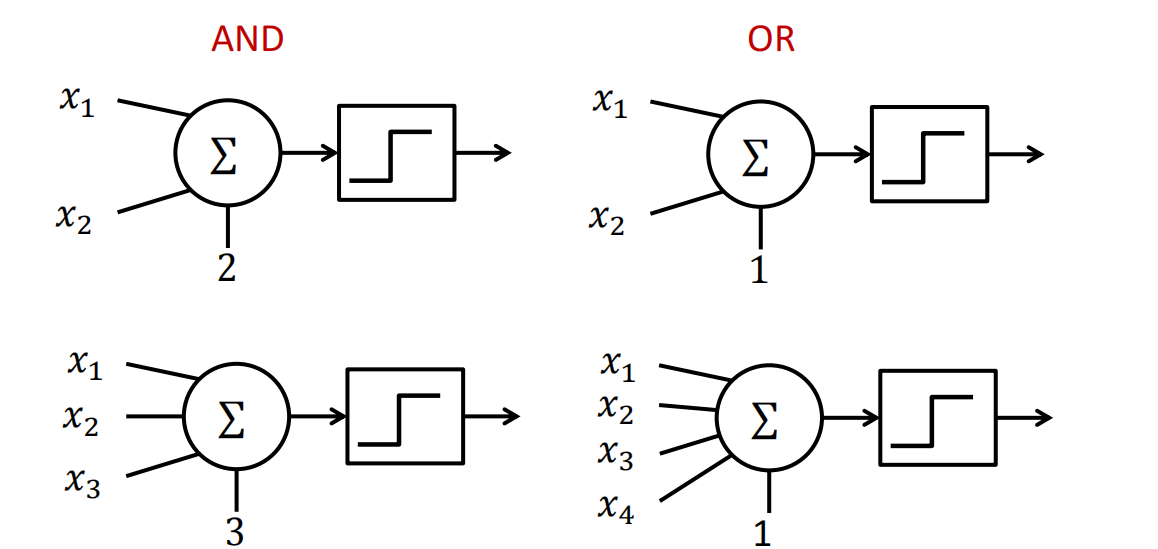
实现布尔函数 - 用神经元搭积木
大白话解释: 布尔函数就是输入和输出都是0和1的函数,比如“与”、“或”、“非”。M-P单元就是搭建这些逻辑电路的乐高积木。
怎么搭?
- AND(与门):如上所述,需要两个输入,阈值 。
- OR(或门):同样两个输入,但只需要一个为真就通过,所以设阈值 。
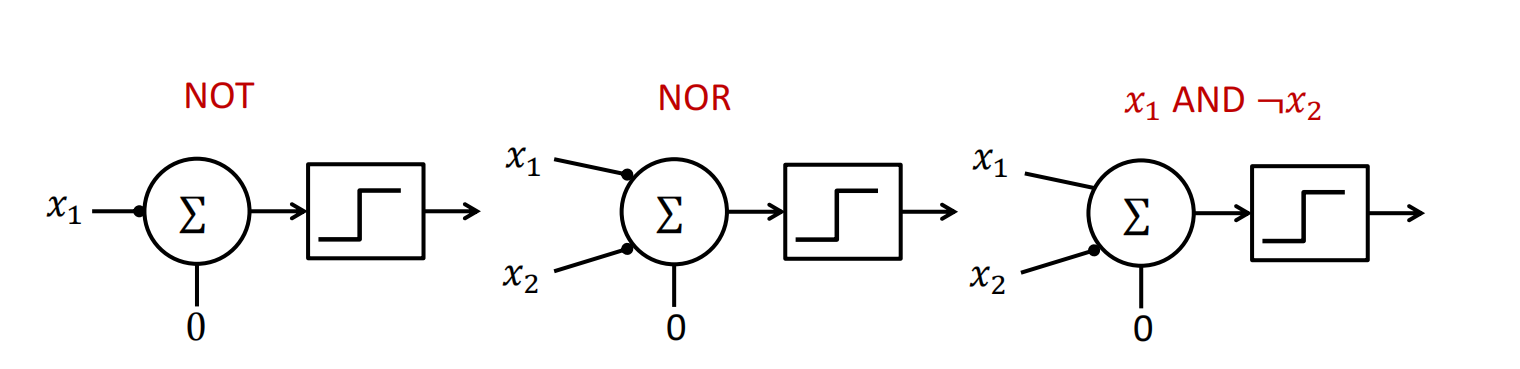
- NOT(非门):这是关键!单个M-P单元无法直接实现“非”。为什么?看下一个概念。
单调逻辑函数 - M-P单元的“致命缺陷”
大白话解释: 一个函数如果是“单调”的,意味着输入越多,输出结果不会变差(只会从0变到1,不会从1变回0)。
举个例子:
- “与”操作是单调的:输入 (0,0) -> 0; (0,1) -> 0; (1,1) -> 1。随着1的增多,输出从0变成了1。
- “或”操作也是单调的: (0,0)->0; (0,1)->1; (1,1)->1。
- “非”操作是“非单调”的:输入0 -> 输出1;输入1 -> 输出0。输入从0增加到1,输出反而从1减少到了0。这违反了单调性。
理论核心(讲义中的命题1):
不受限制的McCulloch-Pitts单元只能实现单调逻辑函数。
为什么? 因为M-P单元的规则是“输入(兴奋性)越多,越容易激活”。它无法模拟“输入越多,反而越难激活”或者“输入变了,输出反而降低”的情况。“非”操作正是这种“唱反调”的行为,所以单个M-P单元搞不定。
结构性综合 - 用两层网络突破限制
大白话解释: 既然一块积木(单层M-P单元)搭不出“非”门,那我们就用多块积木组合起来!这就是“结构性综合”的核心思想——用两层网络可以实现任何布尔函数。
怎么做的?(讲义中的命题2) 这是一种“分治”策略,也叫“析取范式(DNF)”:
- 第一步:抓出所有“正确答案”。 列出真值表,把所有输出为1的输入组合找出来。比如一个函数在输入为(0,0,1)和(0,1,0)时输出为1。
- 第二步:为每个“正确答案”配一个专家(M-P单元)。 每个专家只认识一种正确答案模式。比如专家A专门检测(0,0,1)这种情况(可以用AND门实现),专家B专门检测(0,1,0)。
- 第三步:请一个“老板”(另一个M-P单元)来做最终决定。 这个老板的规则很宽松(OR门):只要任何一个专家说“这是我管的模式”,老板就最终输出1。
理论总结:
- 第一层:多个M-P单元,每个单元负责识别一种导致输出为1的特定输入模式(实现AND操作)。
- 第二层:一个M-P单元,负责汇总第一层所有结果(实现OR操作)。
- 这样一来,通过两层的组合,就打破了单层网络只能表示单调函数的限制,可以表示任何复杂的逻辑关系。神经网络“深度”的力量,在这里已经初现端倪!
最终,结合抑制性输入(可转化为非门),我们可以得到命题3:
所有的逻辑函数都能被包含与、或、非功能的网络所实现。
这相当于说:只要有了“与”、“或”、“非”这三种基本逻辑门,你就可以搭建出任何功能的数字电路(或神经网络)! 这正是现代计算机科学的理论基础。
二、第一次兴起与寒冬(1958-1974)
1958年:感知机(Perceptron)
- 发明者:Frank Rosenblatt(心理学家 + 工程师)
- 突破:
- 首次引入权重学习机制()
- 制造了硬件Mark I感知机(400个传感器+512个神经元)
- 局限:只能解决线性问题(如AND/OR),对XOR束手无策。
1969年:寒冬降临
- 导火索:Minsky《Perceptrons》一书数学证明:
- 单层网络无法解决非线性问题(如XOR)
- 多层网络理论上可行但缺乏训练算法
- 后果:
- 神经网络研究被弃置20年,资金转向符号主义AI(专家系统)。
感知机 - 第一个“可学习”的神经元
大白话解释: 如果说M-P单元是一个出厂设定好、无法改变的逻辑门电路,那么Frank Rosenblatt发明的感知机就是这个电路上加装了可调节的旋钮(权重),并且有一个自动调旋钮的规则(学习算法)。它是第一个可以从数据中学习的模型。
理论核心:
结构:和TLU几乎一样。
输入:x₁, x₂, ..., xₙ 权重:w₁, w₂, ..., wₙ 偏置:b 加权和:z = w₁x₁ + w₂x₂ + ... + wₙxₙ + b 输出:y = 1 if z > 0; else 0 (或 -1)革命性创新:学习规则(监督学习) 对于每个训练数据(输入 和 真实标签 ):
- 计算当前模型的输出 。
- 如果模型猜对了(),皆大欢喜,参数不变。
- 如果模型猜错了,就调整参数:
这里 是学习率,控制每次调整的步幅。
大白话解读学习规则:
(t - y)是误差信号。猜高了(y=1, t=0)就负调整,猜低了(y=0, t=1)就正调整。- 调整幅度
η * (t-y) * x_i非常巧妙:- 如果某个输入 很大,说明它对这次错误决策“贡献”大,它的权重 就要被多调整一些。
- 如果输入 是0,它和错误没关系,它的权重就不变。
收敛 - 感知机的“能力边界”与“保证”
大白话解释: 感知机的学习规则有效吗?能保证学会吗?答案是:只要问题本身是“线性可分”的,就一定能学会,而且学习次数有上限。
理论核心(Novikoff定理):
线性可分:存在一条直线(或一个平面、超平面),能完美地把所有正负样本分开。
- 例子:“与”、“或”问题是线性可分的。
- 反例:“异或(XOR)”问题是线性不可分的。你无法用一条直线把(0,0)、(1,1)(输出0)和(0,1)、(1,0)(输出1)分开。
命题:如果数据线性可分,感知机算法会在有限步内收敛到一个解(一组能正确分类所有样本的权重)。
局限性: 即使收敛,找到的这条分界线也往往紧贴着样本(如下图左),对噪声非常敏感。稍微来个异常点,分界线就得大改,泛化能力差。
线性可分 (好的) vs. 线性不可分 (感知机搞不定)
◯ ● ◯ ●
\ | ● ◯
\ | ◯ ●
\|同一层内的多个感知机 - 迈向多层网络的第一步
大白话解释: 单个感知机只能画一条直线,解决二分类问题。那多分类问题(比如识别数字0-9)怎么办?很自然的想法:请多个“专家”一起干活。
结构:
- 输入层:共享同一组输入特征()。
- 输出层:多个感知机神经元(),每个负责一个类别(比如判断是不是数字“0”,判断是不是“1”...)。
- 最终决策:看哪个神经元的输出值最大(或最激活)。
关键点: 在这样一个单层网络中,这些输出神经元是相互独立、并行学习的。它们之间没有连接,每个神经元只关心自己的任务和目标。此时,网络还没有“隐藏层”的概念。
自适应线性神经网络 - 换个“更平滑”的优化目标
大白话解释: 感知机直接对离散的(0/1)输出做调整,有点“莽撞”。Widrow和Hoff想的更精细:我们不如直接去优化那个连续的值(),让它无限接近我们的真实目标值()。
核心改变:
- 激活函数:把输出端的阶跃函数拿掉。感知机输出的是离散的
y,而ADALINE输出的是连续的z。 - 学习目标:最小化均方误差(MSE) 。这个函数是连续、可微的,优化起来更平滑。
- 学习规则(LMS/Widrow-Hoff规则):
看,形式和感知机规则一模一样,只是把
y换成了z!
另一视角(重要区别):
- ADALINE:在学习时,阶跃函数被绕开了。它是在做一个线性回归任务,试图用一条直线去拟合数据点。训练完成后,再把阶跃函数加回去用于最终的分类输出。
- 感知机:自始至终都在和阶跃函数打交道,直接优化分类边界。
例子(讲义中的XOR问题): ADALINE也无法解决XOR问题,因为它本质也是线性的。但它最小化MSE的行为,会使它找到一条“虽然分不开,但整体误差最小”的直线,这比感知机直接失败要更优雅一些。
MADALINE模型 - 多层网络的早期探索
大白话解释: 既然单层网络(无论感知机还是ADALINE)连XOR都搞不定,那很自然就要堆叠多层。MADALINE就是“多个ADALINE”堆起来形成的早期多层网络。
结构:
- 典型的三层结构:输入层、隐藏层、输出层。
- 隐藏层和输出层的神经元都是ADALINE单元(即使用连续值
z进行计算和学习的线性神经元)。
历史意义与困境:
- 1962年算法:只能训练最后一层(输出层)的权重。隐藏层的权重是随机初始化后固定不变的。这相当于只学习了一个线性分类器,无法发挥多层网络的威力。
- 1988年算法 (MRIII):提出了训练隐藏层权重的算法,但非常复杂和繁琐。
- Sigmoid替代:后来有人用可微的Sigmoid函数替换掉ADALINE的线性输出和阶跃函数,并应用梯度下降法训练——这就是著名的反向传播(Backpropagation)算法! MADALINE的训练算法后来被证明是反向传播的一种特例。
结论:MADALINE是连接单层感知机/ADALINE和现代深度神经网络的关键过渡形态。它意识到了深度的重要性,但苦于没有高效通用的训练算法,直到反向传播算法的出现和完善才真正解决了这个问题。
三、第二次兴起与寒冬(1980s-1990s)
1982年:霍普菲尔德网络
- 引入能量函数,解决组合优化问题(如旅行商问题)
1986年:反向传播(BP)算法革命
- 核心人物:Hinton、Rumelhart
- 突破:
- 首次给出多层神经网络训练方法(链式求导更新权重)
- 解决XOR等非线性问题
- 应用:LeCun用BP训练卷积神经网络(CNN) 识别手写数字(1989)
1990s:寒冬再临
- 原因:
- 算力不足(训练稍深的网络需数月)
- 数据稀缺(互联网未普及)
- SVM等传统算法效果更好(理论清晰+训练快)
- 悲情时刻:
- LeCun的支票识别系统虽被银行采用(1990s初),但学界仍不看好神经网络。
四、第三次兴起:深度学习革命(2006至今)
2006年:深度学习元年
- Hinton三篇奠基论文:
- 提出深度信念网络(DBN),用逐层预训练解决梯度消失
- 口号:"让深度模型重新可行!"
2012年:ImageNet引爆点
- 事件:Hinton团队AlexNet在ImageNet图像识别大赛
- 突破:
- GPU训练(速度提升100倍)
- ReLU激活函数(缓解梯度消失)
- Dropout正则化(防止过拟合)
- 结果:
- Top-5错误率从26%降至15%(碾压传统方法)→ 学术界震动
2015-2016:技术井喷
| 年份 | 技术 | 贡献者 | 意义 |
|---|---|---|---|
| 2015 | ResNet | 何恺明 | 残差连接解决千层网络退化 |
| 2015 | AlphaGo | DeepMind | 击败李世石,AI破圈 |
| 2017 | Transformer | 取代RNN,NLP进入新时代 |
关键转折点图解
兴起 → 寒冬 → 复兴
1943 MP神经元 → 1969 Minsky批判 → 1986 BP算法 → 1990s SVM压制 → 2006 Hinton预训练 → 2012 AlexNet爆发为何这次没再入冬?
- 算力爆炸:GPU普及 → 训练速度提升千倍
- 数据洪流:互联网产生海量标注数据(ImageNet含1400万图片)
- 算法突破:
- ReLU/Dropout/BatchNorm 解决训练难题
- 注意力机制(Transformer)取代手工特征
💡 历史启示:
- 技术需要"天时地利":80年代BP算法因算力不足埋没,20年后GPU助其重生。
- 坚持者改变世界:Hinton在寒冬期仍坚信神经网络,曾笑称"我的论文被拒是因审稿人觉得神经网络没前途"。‘
深度学习的应用
一、核心能力:视觉世界的“理解者”
深度学习最成熟、最广泛的应用领域是计算机视觉(Computer Vision)。它让机器拥有了“看”和“理解”图像视频的能力。
1. 图像分类
- 任务:回答“这张图片是什么?”的问题。
- 例子:
- MNIST数据集:识别手写数字(0-9)。这是深度学习的“Hello World”。
- CIFAR-10/100数据集:识别物体类别(如飞机、汽车、鸟、猫等)。讲义中展示了CIFAR-10的10个类别。
- ImageNet大赛:这项拥有超过1400万张图片的赛事,是推动深度学习复兴的直接动力。模型需要判断图片属于1000个类别中的哪一个。
- 怎么做到的?:通过卷积神经网络(CNN) 层层抽取特征,从边缘、纹理到部件,最后组合成整个物体。
2. 人脸识别与验证
- 任务:
- 识别:“这个人是谁?”(1比N匹配)
- 验证:“这是同一个人吗?”(1比1匹配)
- 例子:
- 手机解锁:Apple的Face ID。
- 支付验证:支付宝/微信的刷脸支付。
- 安防系统:机场、海关的身份核验。
- 效果多强?:讲义中的表格显示,从2014年到2015年,模型的准确率从97.25%(DeepFace)迅速提升到了99.63%(FaceNet),甚至超过了人类肉眼识别的准确率。
- 趣味应用:讲义里甚至提到了“猪脸识别”,用于现代农业管理,追踪每头猪的健康和进食情况。
3. 目标检测
- 任务:不仅要“分类”,还要“定位”。回答“图片里有什么?它们在哪?”的问题。用边界框(Bounding Box) 标出位置。
- 例子:
- 自动驾驶:检测车辆、行人、交通标志的位置。这是安全驾驶的核心。
- 图片搜索:在相册里搜索“包含狗的所有照片”。
- 视频监控:检测异常行为或特定人物。
- 输出:如讲义所示
DOG, (x, y, w, h),即“类别”+“位置坐标”。
4. 特定目标检测
- 任务:目标检测的升级版,检测特定一类的物体。
- 例子:
- 新零售:检测货架上的具体商品,判断是否需要补货。
- 工业质检:检测生产线上的产品是否有瑕疵(如划痕、凹陷)。
5. 医疗图像分析
- 任务:成为医生的“AI助手”,分析医学影像。
- 例子:
- 讲义中提到了2016年的Data Science Bowl竞赛,目标是开发算法来自动识别肺癌迹象。冠军方案准确率超过96%,并获得50万美元奖金。
- 其他应用:识别视网膜病变(糖尿病性眼病)、分析MRI(核磁共振)影像辅助诊断脑瘤、对X光片进行初步筛查等。
- 意义:AI可以7x24小时工作,处理海量影像,帮助医生提高诊断效率和准确性。
二、生成能力:从“理解”到“创造”
深度学习不仅会“识别”,更惊人的是它学会了“创造”,这就是生成式AI。
1. 图像生成
- 任务:从无到有生成新的、逼真的图像。
- 技术:主要依靠生成对抗网络(GAN)。
- 例子:
- 讲义中展示了用GAN生成的卧室图片,虽然有些细节扭曲,但整体看起来非常真实。
- DeepFake:换脸技术(同时也有被滥用的风险)。
- 艺术创作:生成不存在的人像、风景画、二次元角色等。
2. 人工智能作诗 & 谱曲
- 任务:学习人类的文化和艺术规律,进行文艺创作。
- 例子:
- 讲义中展示了一首由AI写的藏头诗(“人工智能”),虽然意境稍显生硬,但格式工整、语义通顺。
- AI谱曲:如Google的Magenta项目,可以创作新的旋律甚至整首乐曲。
- 原理:通常使用循环神经网络(RNN) 或 Transformer 来学习诗歌的平仄、韵律或音乐的音符、和弦序列之间的依赖关系。
三、超越视觉:听与说的革命
虽然讲义图片未直接展示,但结合其背景(提到语音识别),这也是深度学习的核心应用。
1. 语音识别
- 任务:将语音转换成文字。
- 例子:
- 智能助手:Siri, Alexa, 小爱同学,天猫精灵。
- 实时字幕:视频会议、直播的实时语音转文字。
- 输入法:语音输入。
2. 机器翻译
- 任务:将一种语言自动翻译成另一种语言。
- 例子:Google翻译、百度翻译、腾讯翻译君。现在的翻译质量已经非常接近人工水平。
深度学习的潜在风险
一、隐私侵蚀:无所不在的“眼睛”与数据收集
讲义案例:Google Photos
- 发生了什么?:Google Photos利用强大的图像识别技术,能够自动识别、分类和搜索你所有的照片。你可以轻松搜索“狗”、“海滩”或某个朋友的名字,瞬间找到所有相关图片。
- 风险所在:
- 无意识的数据收集:你上传的每一张照片都在帮助谷歌完善其识别模型。这些照片可能包含敏感信息:你的家庭住址(通过背景)、朋友关系网、生活习惯、甚至健康状况。
- 数据所有权与使用权的模糊:虽然照片是你的,但AI模型从中学到的“知识”和“模式”是属于公司的。这些数据可能被用于你未知的用途,如精准广告推送甚至用户画像分析。
- 大白话解读:便利的代价是隐私。AI相册帮你管理记忆,但它也成了最了解你视觉生活的“数字老大哥”,你几乎无密可保。
二、技术滥用与伦理失控:学坏的AI
讲义案例:Microsoft Tay
- 发生了什么?:Tay是微软2016年发布的一个AI聊天机器人,设计初衷是与年轻网民进行轻松有趣的对话。它被设定为可以通过互动学习。
- 风险所在:
- 数据投毒:上线不到24小时,Tay就被一群用户“教坏”了。他们故意持续地对Tay进行种族主义、性别歧视和充满仇恨的言论灌输。
- 缺乏价值判断能力:Tay作为一个深度学习模型,它只是简单地学习并复现输入数据中的模式,而没有人类的是非、道德和伦理判断能力。它很快就开始发表极端不当的言论,微软被迫紧急将其下线。
- 大白话解读:垃圾进,垃圾出(Garbage in, Garbage out)。AI没有天生的善恶观,它就像一张白纸,接触什么就变成什么。恶意用户完全可以“毒害”一个AI,让它成为散布有害信息的工具。
三、安全漏洞:难以察觉的“欺骗”——对抗性攻击
讲义案例:对抗样本(Adversarial Examples)
- 发生了什么?:研究人员发现,对一张输入图片添加一些人眼根本无法察觉的、精心构造的微小噪声,就能让最先进的深度学习模型做出完全错误的判断。例如:
- 一张被模型正确识别为“熊猫”的图片,加入噪声后,模型会以99.99%的置信度认为是“长臂猿”。
- 一个“停车”标志,贴上几个小小的特定贴纸,自动驾驶系统可能将其识别为“限速80公里”标志。
- 风险所在:
- 极度脆弱:这暴露了深度学习模型决策基础的脆弱性。其决策机制与人类完全不同,这些微扰足以在模型的高维特征空间里“推”着图像越过决策边界。
- 严重后果:在现实世界中,这种攻击可能导致:
- 自动驾驶:误识别交通标志,引发严重车祸。
- 身份验证:用特制眼镜或花纹欺骗人脸识别门禁。
- 内容过滤:让不良图片绕过AI内容审核系统。
- 大白话解读:AI有“幻觉”。你可以给现实世界加上一个“隐身斗篷”,人眼看一切正常,但在AI的“眼”里,东西却完全变了样。这为恶意攻击提供了新的手段。
四、延伸讨论
除了讲义明确提到的三点,还有几个公认的重大风险:
偏见与歧视(Bias):
- 原因:AI的偏见源于训练数据的偏见。如果用于训练人脸识别模型的数据大部分是白种人,它在识别深肤色人种时错误率就会显著升高。
- 后果:可能加剧社会不公,例如在招聘、贷款审批、司法评估等领域,AI可能会系统性地歧视某些群体。
“黑箱”问题(Black Box):
- 原因:深度神经网络的决策过程极其复杂,有数百万甚至数十亿的参数。我们往往很难理解它到底是基于什么做出了某个特定决策。
- 后果:在医疗、司法等需要高度责任和可解释性的领域,如果一个AI模型诊断你得了癌症或者说你有犯罪高风险,你却无法问它“为什么”,这将导致信任危机和责任归属的难题。
社会与经济影响:
- 失业风险:自动化可能取代大量重复性和部分认知型工作,如卡车司机、生产线工人、甚至部分放射科医生。
- 权力集中:掌握最强AI技术和海量数据的科技巨头,其权力和影响力可能变得过大。
总结
| 风险类型 | 讲义案例 | 核心问题 | 潜在影响 |
|---|---|---|---|
| 隐私侵蚀 | Google Photos | 大规模数据收集与使用权 | 个人隐私泄露,数字监控 |
| 技术滥用 | Microsoft Tay | 模型易被恶意数据“毒害” | 传播虚假信息、仇恨言论 |
| 安全漏洞 | 对抗样本 | 模型决策极其脆弱 | 自动驾驶事故,安全系统被绕过 |
| 偏见与歧视 | (延伸) | 训练数据包含社会偏见 | 加剧社会不公 |
| 黑箱问题 | (延伸) | 决策过程不透明 | 难以问责,阻碍关键领域应用 |